Was ist Text-zu-Sprache? Ein verständlicher Leitfaden

Text-zu-Sprache (TTS), auch Sprachsynthese genannt, ist Software, die geschriebenen Text in gesprochenes Audio umwandelt. Ein Computer liest einen Satz, analysiert, wie er klingen soll, und gibt eine Audiodatei oder eine Live-Wiedergabe aus. Moderne KI-basierte Text-zu-Sprache-Systeme erzeugen Stimmen, die einer menschlichen Vertonung sehr nahekommen. Deshalb setzen Websites, Apps und Hilfsmittel für Menschen mit Beeinträchtigungen täglich darauf.
Dieser Leitfaden erklärt, was Text-zu-Sprache ist, wie die Technik im Hintergrund funktioniert, was sich mit dem Aufkommen von KI-Stimmen verändert hat und wie Website-Betreiber sie auf echten WordPress-Seiten einsetzen. Wer nach dem Lesen tiefer einsteigen möchte, findet in unserer Anleitung zum Hinzufügen von Text-zu-Sprache in WordPress den nächsten Schritt.
Wie funktioniert Text-zu-Sprache?
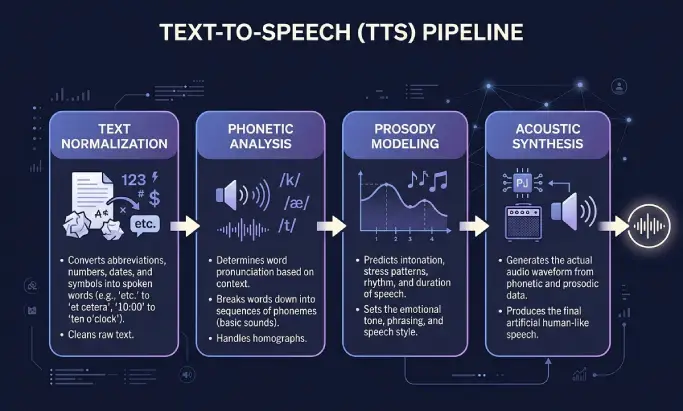
Text-zu-Sprache arbeitet in zwei Phasen. Zuerst wird der geschriebene Text aufbereitet, dann wird das Audio erzeugt. Die meisten Nutzer sehen nur das Ergebnis, doch die Zwischenschritte erklären, warum manche Stimmen flach klingen und andere menschlich wirken.
Textnormalisierung
Das System bereinigt zunächst die Eingabe. Es löst Abkürzungen auf, legt fest, wie Zahlen, Datumsangaben, Währungen und Akronyme ausgesprochen werden, und entfernt Formatierungen, die nicht vorgelesen werden sollen. „Dr. Müller verdiente 1.200 € am 12.5.” wird so aufbereitet, dass die Engine es fehlerfrei aussprechen kann.
Phonetische Analyse
Anschließend zerlegt die Engine Wörter in Phoneme, die kleinsten Lauteinheiten einer Sprache. Hier kommen Ausspracheregeln, Wörterbücher und Sprachmodelle zum Einsatz. Gute Systeme behandeln Homographen korrekt, sodass „modern” als Adjektiv und „modern” als Verb im Kontext unterschiedlich klingen.
Prosodie-Modellierung
Prosodie bezeichnet Rhythmus, Betonung und Intonation der Sprache. Eine Frage steigt am Ende an. Eine Aufzählung hat kurze Pausen zwischen den Punkten. Ein ernster Satz klingt anders als ein heiterer. Eine gute Prosodie-Modellierung ist der Unterschied zwischen einem roboterhaften Vorleser und einem Sprecher, dem man gern zuhört.
Akustische Synthese
Zuletzt erzeugt die Engine die Wellenform. Ältere Systeme setzten vorab aufgenommene Klangfragmente zusammen. Moderne neuronale und generative Engines sagen das Audio direkt aus dem Text mithilfe von Deep Learning voraus. Das Ergebnis ist meist eine MP3-Datei mit 44,1 kHz, die auf Ihrer Website gestreamt oder als Podcast heruntergeladen werden kann.
Von Roboterstimmen zu KI-Stimmen
Frühe Text-zu-Sprache-Systeme arbeiteten konkatenativ. Sie klebten kleine aufgenommene Ausschnitte eines echten Sprechers zusammen, was den abgehackten Klang erklärte. Neuronale TTS ersetzte diesen Ansatz durch statistische Modelle, die Spracheigenschaften vorhersagen und so eine flüssigere Ausgabe liefern. Die aktuelle Generation nutzt generative KI, die auf großen Sprachdatensätzen trainiert wurde und Prosodie, Atemgeräusche und emotionalen Ton auf eine Weise erfasst, die älteren Systemen nicht möglich war.
Diese Entwicklung ist der Grund, warum ein 2026 veröffentlichter Artikel in einer Stimme vertont werden kann, die die meisten Zuhörer im alltäglichen Hören nicht von einem Menschen unterscheiden können. Unsere Stimmbibliothek, powered by ElevenLabs, gehört zu dieser neuesten Generation. Verfügbare Optionen lassen sich in der Stimmen-Dokumentation vorab anhören.
Wer nutzt Text-zu-Sprache und warum?
Text-zu-Sprache steckt in mehr Produkten, als die meisten Menschen ahnen. Dieselbe Kerntechnologie treibt sehr unterschiedliche Anwendungen an.
- Barrierefreiheits-Tools für Leser mit Sehbeeinträchtigung, Legasthenie, geringer Lesekompetenz oder Aufmerksamkeitsschwierigkeiten.
- Audiofassungen von Artikeln auf Nachrichtenseiten, Blogs und Magazinen, damit Leser beim Pendeln oder bei Alltagsaufgaben zuhören können.
- E-Learning-Plattformen, die Lektionen, Quiz und Lernmaterialien in mehreren Sprachen vertonen.
- Vertonungen für Erklärvideos, YouTube-Inhalte und Produkt-Demos, die den Aufwand ersetzen, für jedes Update einen Sprecher zu engagieren.
- WooCommerce-Produktaudio, das Beschreibungen vorliest – praktisch für mobile Nutzer oder Menschen mit Leseschwierigkeiten. Mehr dazu in unserem Leitfaden zu TTS für WooCommerce-Produkte.
- Virtuelle Assistenten und IVR-Systeme, einschließlich der Stimme aus Smart Speakern, Navigations-Apps und Kundenservice-Telefonleitungen.
Welche Vorteile bietet Text-zu-Sprache für Website-Betreiber?
Wer einen Blog, eine Nachrichtenseite, einen Online-Shop oder eine Kursplattform betreibt, erweitert mit Text-zu-Sprache die Reichweite seiner Inhalte. Die Vorteile zeigen sich bei Barrierefreiheit, Reichweite, Engagement und Kosten.
Barrierefreiheit und rechtliche Anforderungen
Eine Audiofassung Ihrer Inhalte hilft Nutzern, die den Bildschirm nicht problemlos lesen können. Sie unterstützt die Einhaltung der Web Content Accessibility Guidelines und des European Accessibility Act, der für viele digitale Dienste im Juni 2025 in Kraft getreten ist. Die praktischen Anforderungen erläutern wir in unseren Beiträgen zu den WCAG-Audioanforderungen für WordPress und dem European Accessibility Act für WordPress-Seiten.
Größere Reichweite
Manche Leser hören lieber zu, auch wenn sie lesen könnten. Pendler, Eltern mit kleinen Kindern, Fitnessstudio-Nutzer und Menschen, die Audio schlicht bevorzugen, werden so erreichbar. Der Artikel wird nicht ersetzt, sondern um einen zweiten Konsumweg ergänzt.
Längere Verweildauer und mehr Engagement
Audio-Wiedergabe hält Nutzer für die gesamte Länge des Artikels auf der Seite, statt nur kurz zu scrollen. Selbst teilweises Zuhören erhöht die messbare Verweildauer, ein Signal, auf das sowohl Google als auch Empfehlungssysteme achten. In unserer Auswertung verzeichnen Beiträge mit Audio-Player eine höhere durchschnittliche Sitzungsdauer als dieselben Beiträge ohne.
AEO und Zitierung durch KI-Suchmaschinen
Antwort-Engines wie Google AI Overviews, Perplexity und ChatGPT Search bevorzugen zunehmend Inhalte mit klarer Struktur und unterstützenden Medien. Audio ist eines dieser Signale. Wir haben das in warum KI-Suchmaschinen Artikel mit Audio bevorzugen ausführlich aufgeschlüsselt.
Mehrsprachiges Audio ohne Neuaufnahmen
Wenn Ihre Website mit Weglot, WPML oder Polylang übersetzt wird, kann modernes TTS jede Sprachversion automatisch mit einer nativ klingenden Stimme vertonen. Diesen Ablauf haben wir in unserem Leitfaden zu Text-zu-Sprache mit Weglot dokumentiert. Für jede Sprache einen Sprecher neu aufzunehmen ist teuer. Eine Stimme pro Sprache zuzuweisen dauert Minuten.
Geringere Kosten als professionelle Sprecher
Ein professioneller Sprecher für einen einzigen Artikel mit 1.500 Wörtern kann mehr kosten als ein Monatsbudget an generativem TTS-Guthaben, das den gesamten Blog abdeckt. Für die meisten Publisher ist der Vergleich eindeutig. Der Kompromiss liegt bei der kreativen Kontrolle, weshalb manche Podcasts und Markenkampagnen weiterhin auf menschliche Stimmen setzen. Für tägliche Artikel gewinnt die KI-Vertonung.
Text-zu-Sprache vs. Sprache-zu-Text: Was ist der Unterschied?
Text-zu-Sprache und Sprache-zu-Text sind Gegenstücke. Text-zu-Sprache nimmt geschriebene Wörter und erzeugt Audio. Sprache-zu-Text nimmt Audio und erzeugt geschriebenen Text. Beide lösen unterschiedliche Probleme und treten oft im selben Produkt auf.
| Funktion | Text-zu-Sprache (TTS) | Sprache-zu-Text (STT) |
|---|---|---|
| Eingabe | Geschriebener Text | Gesprochenes Audio |
| Ausgabe | Audiodatei oder Live-Wiedergabe | Geschriebenes Transkript |
| Typische Nutzung | Artikelvertonung, Voiceover, Assistenten | Transkription, Diktat, Untertitel, Suche |
| Auch bekannt als | Vorlesen, Sprachsynthese | ASR, Spracherkennung |
Die meisten modernen Audioplattformen bieten beides. Ein Podcast-Anbieter könnte STT nutzen, um eine Episode zu transkribieren, und TTS, um eine Audiozusammenfassung in einer anderen Sprache zu erstellen.
Wie fügen Sie Text-zu-Sprache Ihrer eigenen Website hinzu?
Auf WordPress fügen Sie Text-zu-Sprache über ein Plugin hinzu. Das Plugin übernimmt die Stimmauswahl, die automatische Generierung beim Veröffentlichen und den Audio-Player, den Ihre Besucher sehen. Text-zu-Sprache - TTSWP ist unser Ansatz in dieser Kategorie, gebaut für Publisher statt für Entwickler.
Einen Vergleich der Optionen bietet unser Überblick der besten Text-zu-Sprache-Plugins für WordPress. Wer direkt loslegen möchte, findet alle Informationen zu den Funktionen von TTSWP und zur Preisgestaltung. Die Schritt-für-Schritt-Installation erklärt unser Einrichtungsleitfaden.
Häufig gestellte Fragen
Was ist Text-zu-Sprache einfach erklärt?
Text-zu-Sprache ist Software, die geschriebenen Text vorliest. Sie übergeben einen Absatz oder Artikel, und das System gibt eine Audiodatei oder eine Live-Wiedergabe in einer gewählten Stimme und Sprache zurück. Es ist dieselbe Technologie hinter Audiofassungen von Nachrichtenartikeln, Screenreadern, Sprachassistenten und der Ansagestimme in Navigations-Apps.
Wofür wird Text-zu-Sprache verwendet?
Text-zu-Sprache wird für Barrierefreiheit, Audiofassungen von Texten, E-Learning-Vertonungen, Voiceovers für Videos, Produktbeschreibungsaudio in Online-Shops und virtuelle Assistenten eingesetzt. Websites nutzen es, um Artikel in hörbares Audio umzuwandeln. Apps lesen damit Nachrichten, Routen und Hinweise vor. Schulen machen Lernmaterialien so für mehr Lernende zugänglich.
Ist Text-zu-Sprache kostenlos?
Einige Text-zu-Sprache-Lösungen sind kostenlos, aber die Qualität schwankt stark. Betriebssysteme enthalten einfache TTS ohne Kosten, und Browser bieten eine kostenlose Web Speech API. Diese Stimmen klingen merklich roboterhaft. Hochwertige KI-Stimmen von Anbietern wie ElevenLabs nutzen ein Guthaben-Modell. TTSWP bietet einen kostenlosen Einstieg, damit Sie die Qualität testen können. Mit kostenpflichtigen Plänen erhalten Sie Zugang zu mehr Stimmen, Sprachen und monatlichen Zeichen.
Ist Text-zu-Sprache dasselbe wie ein Screenreader?
Nein. Ein Screenreader ist ein Hilfsprogramm wie NVDA, JAWS, VoiceOver oder TalkBack, das die gesamte Oberfläche vorliest, einschließlich Menüs, Links und Formularfelder. Text-zu-Sprache ist die zugrunde liegende Stimmtechnologie, die ein Screenreader nutzt. TTS allein liest jedoch nur den Inhalt vor, auf den Sie es ausrichten, etwa den Textkörper eines Artikels.
Darf ich KI-Text-zu-Sprache-Stimmen kommerziell auf meinem Blog verwenden?
Ja, sofern Ihr Anbieter die Stimmen für kommerzielle Nutzung lizenziert. ElevenLabs, die Engine hinter TTSWP, schließt kommerzielle Rechte in bezahlten Plänen ein. Die genauen Nutzungsbedingungen sollten Sie dennoch für Ihren konkreten Anwendungsfall lesen, besonders bei monetarisierten Podcasts, Werbung oder dem Weiterverkauf von Audio. Für einen Standard-Blog mit Audiofassungen eigener Artikel ist die kommerzielle Nutzung abgedeckt.
Wie natürlich klingen KI-Text-zu-Sprache-Stimmen heute?
Moderne generative TTS klingt im alltäglichen Zuhören nah an einer menschlichen Stimme. Die meisten Hörer erkennen es beim ersten Durchgang nicht als synthetisch. Bei langer Vertonung, ausdrucksstarken Dialogen und starken Akzenten ist der Unterschied manchmal noch spürbar. Für Nachrichtenartikel, Blogbeiträge und Produktbeschreibungen ist der Abstand zu einem menschlichen Sprecher so gering, dass die meisten Publisher es als gelöst betrachten.
Funktioniert Text-zu-Sprache auch in anderen Sprachen als Englisch?
Ja. Hochwertige generative TTS unterstützt Dutzende von Sprachen mit nativ klingenden Stimmen, darunter die wichtigsten europäischen, asiatischen und arabischen Sprachen. TTSWP weist jeder Sprache eine eigene Stimme zu, sodass eine mehrsprachige Website jede Übersetzung korrekt vertont. Die Konfiguration erfolgt einmalig in den Einstellungen, neue Beiträge verwenden automatisch die richtige Stimme.
Wie geht es weiter?
Wer auf WordPress publiziert und eine Audiofassung jedes Artikels haben möchte, ohne selbst aufzunehmen, kommt am schnellsten ans Ziel: Text-zu-Sprache - TTSWP installieren, die Website verbinden und eine Stimme auswählen. Sie können kostenlos loslegen und haben die erste Audiodatei in wenigen Minuten. Danach bleibt nur noch das Schreiben.
Verwandte Artikel
European Accessibility Act und WordPress: Leitfaden zur EAA-Konformität 2026
Was der European Accessibility Act für WordPress-Betreiber in 2026 bedeutet, wen er betrifft, welche Bußgelder drohen und welche Pflichten oft übersehen werden.

WCAG 2.2 Audio-Konformität für WordPress: Leitfaden 2026
WordPress-Audio muss WCAG 2.2-Kriterien erfüllen, darunter Zielgröße, Tastaturzugang und Audio-Steuerung. Hier ist die praktische Compliance-Checkliste für 2026.

Text-zu-Sprache mit TranslatePress: Was funktioniert
TranslatePress übersetzt gerendertes HTML, nicht duplizierte Beiträge. So lässt sich Text-zu-Sprache für jede Sprache korrekt einrichten, ohne fehlerhafte Audiodateien.