Что такое синтез речи? Понятное руководство

Синтез речи (TTS) — это программа, которая преобразует написанный текст в голосовое аудио. Система считывает предложение, анализирует, как оно должно звучать, и выдаёт аудиофайл или воспроизводит звук в реальном времени. Современные системы синтеза речи на основе ИИ создают голоса, практически неотличимые от живого диктора, — именно поэтому сайты, приложения и вспомогательные технологии используют их каждый день.
Это руководство объясняет, что такое синтез речи, как он устроен внутри, что изменилось с появлением ИИ-голосов и как владельцы сайтов применяют его на реальных WordPress-проектах. Если после прочтения вы захотите разобраться с настройкой, наша инструкция по теме добавления синтеза речи на WordPress продолжит там, где заканчивается эта статья.
Как работает синтез речи?
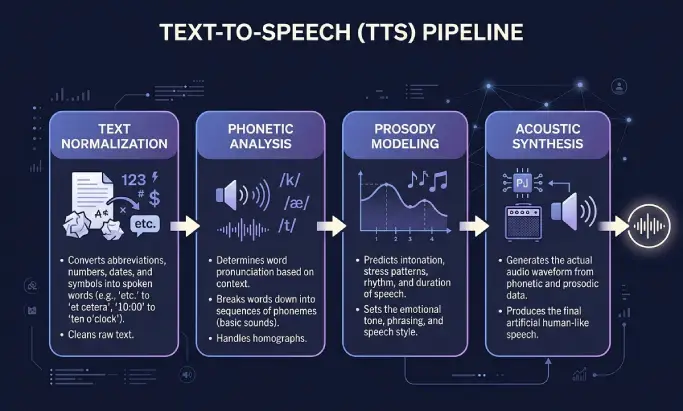
Синтез речи работает в два этапа. Первый — обработка входного текста, второй — генерация аудио. Большинство пользователей видят только результат, но именно промежуточные шаги объясняют, почему одни голоса звучат плоско, а другие — по-человечески.
Нормализация текста
Сначала система очищает входные данные. Она раскрывает сокращения, определяет, как читать числа, даты, валюты и аббревиатуры, и удаляет форматирование, которое не нужно произносить. Фраза «д-р Смирнов заработал 75 000 ₽ 12.05» превращается в строку, которую движок может произнести без угадывания.
Фонетический анализ
Затем движок переводит слова в фонемы — минимальные единицы звука в языке. Здесь в дело вступают правила произношения, словари и языковые модели. Хорошие системы правильно обрабатывают омографы: слова, которые пишутся одинаково, но произносятся по-разному в зависимости от контекста.
Моделирование просодии
Просодия — это ритм, ударение и интонация речи. Вопрос поднимает тон в конце. Перечисление требует небольших пауз между элементами. Серьёзная фраза звучит иначе, чем бодрая. Качественное моделирование просодии — это разница между роботом, считывающим текст, и диктором, которого хочется слушать.
Акустический синтез
На последнем этапе движок генерирует звуковую волну. Старые системы склеивали заранее записанные фрагменты речи. Современные нейронные и генеративные движки предсказывают аудио напрямую из текста с помощью глубокого обучения. Результат — обычно MP3 или похожий формат с частотой дискретизации 44,1 кГц, который транслируется на сайте или скачивается как подкаст.
От роботизированных голосов к ИИ-голосам
Ранние системы синтеза речи были конкатенативными: они склеивали небольшие записанные фрагменты реального диктора, из-за чего звучали отрывисто. Нейронный TTS заменил этот подход статистическими моделями, предсказывающими речевые характеристики, — результат стал более плавным. Нынешнее поколение использует генеративный ИИ, обученный на больших наборах речевых данных, и воспроизводит просодию, дыхание и эмоциональный тон так, как старые системы не могли.
Именно этот сдвиг позволяет озвучивать статьи голосом, который большинство слушателей при обычном прослушивании не отличат от живого. Библиотека голосов TTSWP, работающая на базе ElevenLabs, относится к этому новейшему поколению. Просмотреть доступные варианты можно в документации по голосам.
Кто и зачем использует синтез речи?
Синтез речи встречается в значительно большем числе мест, чем большинство людей думает. Одна и та же технология лежит в основе совершенно разных продуктов.
- Инструменты доступности для людей с нарушениями зрения, дислексией, низким уровнем грамотности или трудностями с концентрацией внимания.
- Аудиоверсии статей на новостных сайтах, в блогах и журналах — чтобы слушать по дороге на работу или во время домашних дел.
- Платформы онлайн-обучения, озвучивающие уроки, тесты и учебные материалы на нескольких языках.
- Закадровый голос для обучающих видео, YouTube-контента и демонстраций продуктов — без необходимости нанимать диктора при каждом обновлении.
- Аудио описаний товаров в WooCommerce — удобно для покупателей на мобильных устройствах или с трудностями при чтении. Подробнее об этом в нашем руководстве по TTS для товаров WooCommerce.
- Виртуальные помощники и IVR-системы, включая голос умных колонок, навигационных приложений и телефонных линий поддержки клиентов.
Какую пользу синтез речи приносит владельцам сайтов?
Если у вас блог, новостной портал, интернет-магазин или образовательная платформа, синтез речи расширяет возможности вашего контента. Преимущества охватывают доступность, охват аудитории, вовлечённость и экономию.
Доступность и соответствие требованиям законодательства
Аудиоверсия текстового контента помогает пользователям, которым сложно читать с экрана. Она поддерживает соответствие Руководству по доступности веб-контента (WCAG) и Европейскому акту о доступности, вступившему в силу для многих цифровых сервисов в июне 2025 года. Практические требования мы разбираем в статьях о требованиях WCAG к аудио для WordPress и Европейском акте о доступности для WordPress-сайтов.
Расширение аудитории
Часть читателей предпочтёт послушать, даже если могла бы прочитать. Люди в дороге, родители с маленькими детьми, посетители спортзала и те, кто просто любит аудио, становятся вашей аудиторией. Вы не заменяете статью — вы добавляете второй способ её потребления.
Более долгое время на сайте и вовлечённость
Аудиоплеер удерживает пользователей на странице на время всей статьи, а не на секунды быстрой прокрутки. Даже частичное прослушивание заметно увеличивает время на странице — сигнал, на который обращают внимание и Google, и рекомендательные алгоритмы. На практике посты с аудиоплеером показывают более высокую среднюю продолжительность сессии, чем те же публикации без него.
AEO и попадание в ответы ИИ-поисковиков
Ответные системы — Google AI Overviews, Perplexity и ChatGPT Search — всё чаще цитируют контент с чёткой структурой и дополнительными медиаматериалами. Аудио является одним из таких сигналов. Мы подробно разобрали это в статье о том, почему ИИ-поисковики отдают предпочтение статьям с аудио.
Многоязычное аудио без перезаписи
Если ваш сайт переведён с помощью Weglot, WPML или Polylang, современный TTS может автоматически озвучить каждую языковую версию нативным голосом для соответствующей локали. Этот процесс мы описали в руководстве по синтезу речи с Weglot. Перезапись диктора для каждого языка обходится дорого. Назначить голос для каждого языка — дело нескольких минут.
Дешевле, чем нанимать диктора
Профессиональный диктор для одной статьи на 1500 слов может стоить дороже, чем месячная подписка на генеративный TTS, покрывающая весь блог. Для большинства издателей выбор очевиден. Разница в творческом контроле — поэтому некоторые подкасты и брендовые кампании по-прежнему работают с живыми дикторами. Для ежедневных статей ИИ-озвучка побеждает.
Синтез речи и распознавание речи: в чём разница?
Синтез речи и распознавание речи — противоположные технологии. Синтез берёт текст и создаёт аудио. Распознавание берёт аудио и создаёт текст. Они решают разные задачи и часто встречаются в одних и тех же продуктах.
| Характеристика | Синтез речи (TTS) | Распознавание речи (STT) |
|---|---|---|
| Входные данные | Текст | Голосовое аудио |
| Выходные данные | Аудиофайл или воспроизведение в реальном времени | Текстовая расшифровка |
| Типичное применение | Озвучивание статей, закадровый голос, помощники | Транскрипция, диктовка, субтитры, поиск |
| Другие названия | Озвучивание текста, речевой синтез | ASR, голосовое распознавание |
Большинство современных аудиоплатформ включают обе технологии. Хостинг подкастов может использовать STT для расшифровки выпуска и TTS для генерации аудиосаммари на другом языке.
Как добавить синтез речи на свой сайт?
На WordPress это делается с помощью плагина. Плагин берёт на себя выбор голоса, автоматическую генерацию при публикации и отображение аудиоплеера для посетителей. Синтез речи - TTSWP — наш подход к этой задаче, созданный для издателей, а не разработчиков.
Сравнить варианты можно в нашем обзоре лучших плагинов синтеза речи для WordPress. Или сразу посмотрите, что умеет TTSWP, и изучите тарифы. Пошаговая установка описана в нашем руководстве по настройке.
Часто задаваемые вопросы
Что такое синтез речи простыми словами?
Синтез речи — это программа, которая читает текст вслух. Вы передаёте ей абзац или статью, а она возвращает аудиофайл или воспроизводит звук в выбранном голосе и на нужном языке. Именно эта технология работает в аудиоверсиях новостных статей, программах чтения с экрана, голосовых помощниках и объявлениях навигационных приложений.
Где применяется синтез речи?
Синтез речи используется для обеспечения доступности, создания аудиоверсий текстового контента, озвучивания уроков в онлайн-обучении, закадрового голоса в видео, аудиоописаний товаров в интернет-магазинах и виртуальных помощников. Сайты применяют его, чтобы превратить статьи в аудио для прослушивания. Приложения — чтобы зачитывать сообщения, маршруты и уведомления. Учебные платформы — чтобы сделать материалы доступными для большего числа учащихся.
Синтез речи бесплатный?
Базовые инструменты синтеза речи существуют бесплатно, но их качество сильно различается. Операционные системы включают простой TTS без дополнительных затрат, а браузеры открывают доступ к бесплатному Web Speech API. Все эти голоса звучат заметно роботизированно. Высококачественные ИИ-голоса от таких провайдеров, как ElevenLabs, работают по кредитной модели. TTSWP предлагает бесплатный тариф, чтобы вы могли оценить результат, а платные планы открывают доступ к большему числу голосов, языков и символов в месяц.
Синтез речи — это то же самое, что программа чтения с экрана?
Нет. Программа чтения с экрана — это вспомогательное приложение (NVDA, JAWS, VoiceOver, TalkBack), которое читает весь интерфейс: меню, ссылки, поля форм. Синтез речи — это базовая голосовая технология, которую такая программа использует. Сам по себе TTS озвучивает только тот контент, на который вы его направите, например текст статьи.
Можно ли использовать ИИ-голоса в коммерческих целях на блоге?
Да, если провайдер лицензирует голоса для коммерческого использования. ElevenLabs, движок за TTSWP, включает коммерческие права в платные планы. Всё же стоит прочитать условия для вашего конкретного случая — особенно если речь идёт о монетизированных подкастах, рекламе или перепродаже аудио. Для стандартного блога с аудиоверсиями собственных статей коммерческое использование предусмотрено.
Насколько естественно звучат современные ИИ-голоса?
Современный генеративный TTS при обычном прослушивании звучит близко к живому голосу. Большинство слушателей не распознают синтез с первого раза. Длинные нарративы, выразительные диалоги и сильные акценты — места, где отличие ещё заметно. Для новостных статей, блог-постов и описаний товаров разрыв с живым диктором настолько мал, что большинство издателей считают эту задачу решённой.
Синтез речи работает на других языках, кроме английского?
Да. Качественный генеративный TTS поддерживает десятки языков с нативными голосами, включая основные европейские, азиатские и ближневосточные. TTSWP назначает отдельный голос для каждого языка, чтобы многоязычный сайт озвучивал каждый перевод правильно. Настроить это нужно один раз, и новые публикации будут автоматически использовать нужный голос.
Что делать дальше
Если вы публикуете материалы на WordPress и хотите аудиоверсию каждой статьи без самостоятельной записи, самый быстрый путь — установить Синтез речи - TTSWP, подключить сайт и выбрать голос. Начните бесплатно — первый аудиофайл будет готов уже через несколько минут. Дальше остаётся только писать.
Похожие статьи
Европейский акт о доступности и WordPress: руководство по соответствию 2026
Что Европейский акт о доступности означает для владельцев сайтов на WordPress в 2026 году: кто обязан соблюдать требования, какие штрафы предусмотрены и о каком заявлении о доступности почти никто не говорит.

WCAG 2.2 и аудио на WordPress: руководство 2026 года
Аудио на WordPress должно соответствовать критериям WCAG 2.2: минимальный размер кнопок, управление с клавиатуры и контроль воспроизведения. Практический чеклист соответствия на 2026 год.

Синтез речи для TranslatePress: что работает и как
TranslatePress переводит готовый HTML, а не создаёт дубли постов. Разбираем, как настроить синтез речи для каждого языка без сломанного аудио.