Apa Itu Teks ke Ucapan? Panduan Lengkap dalam Bahasa Sederhana

Teks ke Ucapan (TTS), yang juga dikenal sebagai teknologi baca-keras atau sintesis ucapan, adalah perangkat lunak yang mengubah teks tertulis menjadi audio yang bisa didengar. Komputer membaca sebuah kalimat, menganalisis bagaimana kalimat itu seharusnya terdengar, lalu menghasilkan file audio atau pemutaran langsung. Sistem teks ke ucapan berbasis AI modern menghasilkan suara yang sangat mirip dengan narator manusia, itulah mengapa situs web, aplikasi, dan alat bantu aksesibilitas mengandalkannya setiap hari.
Panduan ini menjelaskan apa itu teks ke ucapan, cara kerjanya di balik layar, apa yang berubah ketika suara AI hadir, dan bagaimana pemilik situs web menggunakannya di situs WordPress nyata. Jika Anda ingin panduan praktis setelah membaca ini, artikel kami tentang cara menambahkan teks ke ucapan ke WordPress melanjutkan dari sini.
Bagaimana cara kerja teks ke ucapan?
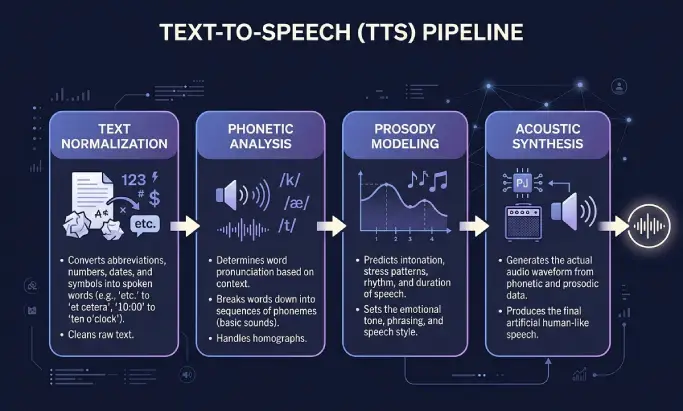
Teks ke ucapan bekerja dalam dua tahap. Bagian pertama memproses teks tertulis, dan bagian kedua menghasilkan audio. Sebagian besar pengguna hanya melihat hasilnya, tetapi langkah-langkah di antaranya menjelaskan mengapa sebagian suara terdengar datar dan yang lain terdengar seperti manusia.
Normalisasi teks
Sistem pertama-tama membersihkan input. Sistem memperluas singkatan, memutuskan cara membaca angka, tanggal, mata uang, dan akronim, serta menghapus format yang tidak perlu diucapkan. "Dr. Smith menghasilkan Rp 18.000.000 pada 5/12" menjadi sesuatu yang dapat diucapkan oleh mesin tanpa harus menebak.
Analisis fonetik
Selanjutnya, mesin mengubah kata-kata menjadi fonem, yaitu unit suara terkecil dalam suatu bahasa. Di sinilah aturan pelafalan, kamus, dan model bahasa berperan. Sistem yang baik menangani homonim dengan benar, sehingga kata yang sama memiliki pengucapan berbeda sesuai konteksnya.
Pemodelan prosodi
Prosodi adalah ritme, tekanan, dan intonasi dalam ucapan. Kalimat tanya nadanya naik di akhir. Sebuah daftar memiliki jeda kecil di antara item. Kalimat serius terdengar berbeda dari kalimat yang santai. Pemodelan prosodi yang baik adalah perbedaan antara pembaca yang terdengar robotik dan narator yang benar-benar enak didengarkan.
Sintesis akustik
Terakhir, mesin menghasilkan gelombang suara. Sistem lama menyambungkan fragmen suara yang telah direkam sebelumnya. Mesin neural dan generatif modern memprediksi audio langsung dari teks menggunakan deep learning. Hasilnya biasanya berupa file MP3 atau format serupa pada 44,1 kHz, yang dapat diputar di situs Anda atau diunduh sebagai podcast.
Dari suara robotik ke suara AI
Sistem teks ke ucapan awal bersifat konkatenatif. Sistem tersebut menyambungkan klip rekaman kecil dari pembicara nyata, itulah mengapa suaranya terdengar putus-putus. Neural TTS menggantikan pendekatan itu dengan model statistik yang memprediksi fitur ucapan, menghasilkan output yang lebih halus. Generasi saat ini menggunakan AI generatif yang dilatih pada kumpulan data ucapan besar, yang mampu menangkap prosodi, napas, dan nada emosional dengan cara yang tidak bisa dilakukan sistem lama.
Itulah mengapa sebuah artikel yang diterbitkan pada 2026 bisa dinarasikan dalam suara yang sebagian besar pendengar tidak bisa bedakan dari manusia saat mendengar sekilas. Perpustakaan suara kami, yang didukung oleh ElevenLabs, berada di generasi terbaru ini. Anda bisa melihat pratinjau pilihan yang tersedia di dokumentasi suara.
Siapa yang menggunakan teks ke ucapan dan untuk apa?
Teks ke ucapan ada di lebih banyak tempat dari yang kebanyakan orang sadari. Teknologi inti yang sama mendukung produk-produk yang sangat berbeda.
- Alat aksesibilitas bagi pembaca dengan gangguan penglihatan, disleksia, kemampuan literasi rendah, atau kesulitan konsentrasi.
- Versi audio dari artikel di situs berita, blog, dan majalah, agar pembaca bisa mendengarkan saat bepergian atau mengerjakan pekerjaan rumah.
- Platform e-learning yang menarasikan pelajaran, kuis, dan panduan belajar dalam berbagai bahasa.
- Narasi suara untuk video penjelasan, konten YouTube, dan demo produk, menggantikan biaya menyewa pengisi suara untuk setiap pembaruan.
- Audio produk WooCommerce yang membacakan deskripsi dengan suara, berguna bagi pembeli di perangkat mobile atau yang mengalami kesulitan membaca. Kami membahas ini secara rinci di panduan TTS untuk produk WooCommerce.
- Asisten virtual dan sistem IVR, termasuk suara yang Anda dengar dari speaker pintar, aplikasi navigasi, dan jalur telepon layanan pelanggan.
Apa manfaat teks ke ucapan bagi pemilik situs web?
Jika Anda mengelola blog, situs berita, toko online, atau platform kursus, teks ke ucapan mengubah apa yang bisa dilakukan konten Anda. Manfaatnya mencakup aksesibilitas, jangkauan, keterlibatan pengguna, dan penghematan biaya.
Aksesibilitas dan kepatuhan hukum
Versi audio dari konten tertulis Anda membantu pengguna yang tidak bisa membaca layar dengan nyaman. Ini mendukung kepatuhan terhadap Panduan Aksesibilitas Konten Web dan Undang-Undang Aksesibilitas Eropa, yang mulai berlaku untuk banyak layanan digital pada Juni 2025. Kami menguraikan persyaratan praktisnya di artikel tentang persyaratan audio WCAG untuk WordPress dan Undang-Undang Aksesibilitas Eropa untuk situs WordPress.
Jangkauan audiens yang lebih luas
Sebagian pembaca akan mendengarkan meski mereka bisa membaca. Penumpang yang bepergian, orang tua dengan anak kecil, pengguna gym, dan mereka yang lebih suka audio semuanya bisa dijangkau. Anda tidak mengganti artikel. Anda menambahkan cara kedua untuk mengonsumsinya.
Durasi kunjungan dan keterlibatan yang lebih lama
Pemutaran audio membuat pengguna berada di halaman selama durasi artikel, bukan hanya sekadar menggulir cepat. Bahkan mendengarkan sebagian saja sudah menambah waktu di halaman yang terukur, yang menjadi sinyal yang diperhatikan Google dan sistem rekomendasi. Dalam pengaturan kami, artikel dengan pemutar audio memiliki rata-rata durasi sesi yang lebih tinggi dibanding artikel yang sama tanpa pemutar.
AEO dan kutipan oleh mesin pencari AI
Mesin jawaban seperti Google AI Overviews, Perplexity, dan ChatGPT Search semakin sering mengutip konten yang terstruktur dengan baik dan memiliki media pendukung. Audio adalah salah satu sinyal tersebut. Kami menulis uraian khusus tentang ini di artikel mengapa mesin pencari AI lebih menyukai artikel dengan audio.
Audio multibahasa tanpa perlu merekam ulang
Jika situs Anda diterjemahkan dengan Weglot, WPML, atau Polylang, TTS modern dapat menarasikan setiap versi bahasa secara otomatis menggunakan suara yang terdengar seperti penutur asli bahasa tersebut. Kami mendokumentasikan alur kerja ini di panduan teks ke ucapan dengan Weglot. Merekam ulang pengisi suara manusia untuk setiap bahasa membutuhkan biaya besar. Memetakan satu suara per bahasa hanya butuh beberapa menit.
Biaya lebih rendah dibanding menyewa pengisi suara
Seorang narator profesional untuk satu artikel 1.500 kata bisa menghabiskan biaya lebih dari sebulan kredit TTS generatif yang mencakup seluruh blog Anda. Bagi sebagian besar penerbit, perhitungannya sudah jelas. Kekurangannya adalah kontrol kreatif, itulah mengapa sebagian podcast dan kampanye merek masih menggunakan pengisi suara manusia. Untuk artikel harian, narasi AI adalah pilihan yang lebih masuk akal.
Teks ke ucapan vs ucapan ke teks: apa bedanya?
Teks ke ucapan dan ucapan ke teks adalah kebalikan satu sama lain. Teks ke ucapan mengambil kata-kata tertulis dan menghasilkan audio. Ucapan ke teks mengambil audio dan menghasilkan kata-kata tertulis. Keduanya memecahkan masalah yang berbeda dan sering muncul dalam produk yang sama.
| Kemampuan | Teks ke Ucapan (TTS) | Ucapan ke Teks (STT) |
|---|---|---|
| Input | Teks tertulis | Audio yang diucapkan |
| Output | File audio atau pemutaran langsung | Transkrip tertulis |
| Penggunaan umum | Narasi artikel, narasi suara, asisten | Transkripsi, dikte, teks, pencarian |
| Juga disebut | Baca-keras, sintesis ucapan | ASR, pengenalan suara |
Sebagian besar platform audio modern mencakup keduanya. Sebuah layanan podcast bisa menggunakan STT untuk mentranskrip episode dan TTS untuk menghasilkan ringkasan audio dalam bahasa lain.
Bagaimana cara menambahkan teks ke ucapan ke situs Anda?
Di WordPress, Anda menambahkan teks ke ucapan dengan sebuah plugin. Plugin tersebut menangani pemilihan suara, pembuatan otomatis saat Anda menerbitkan, dan pemutar audio yang dilihat pengunjung Anda. Teks ke Ucapan - TTSWP adalah solusi kami di kategori ini, yang dibangun untuk para penerbit bukan pengembang.
Anda bisa membandingkan pilihan di rangkuman kami tentang plugin teks ke ucapan terbaik untuk WordPress, atau langsung ke apa yang bisa dilakukan TTSWP dan harga. Panduan instalasi langkah demi langkah tersedia di panduan pengaturan kami.
Pertanyaan yang sering diajukan
Apa itu teks ke ucapan dalam bahasa sederhana?
Teks ke ucapan adalah perangkat lunak yang membacakan teks tertulis dengan suara. Anda memberikannya sebuah paragraf atau artikel, dan hasilnya adalah file audio atau pemutaran langsung dalam suara dan bahasa yang dipilih. Ini adalah teknologi yang sama di balik versi audio artikel berita, pembaca layar, asisten suara, dan suara pengumuman di aplikasi navigasi.
Untuk apa teks ke ucapan digunakan?
Teks ke ucapan digunakan untuk aksesibilitas, versi audio dari konten tertulis, narasi e-learning, narasi suara untuk video, audio deskripsi produk di toko online, dan asisten virtual. Situs web menggunakannya untuk mengubah artikel menjadi audio yang bisa didengarkan. Aplikasi menggunakannya untuk membacakan pesan, petunjuk arah, dan notifikasi. Sekolah menggunakannya agar materi belajar bisa diakses oleh lebih banyak pelajar.
Apakah teks ke ucapan gratis?
Sebagian teks ke ucapan gratis, tetapi kualitasnya bervariasi. Sistem operasi menyertakan TTS dasar tanpa biaya, dan browser menyediakan Web Speech API gratis. Suara-suara ini terdengar cukup robotik. Suara AI berkualitas tinggi dari penyedia seperti ElevenLabs menggunakan model kredit. TTSWP menawarkan paket gratis agar Anda bisa mencoba pengalamannya, lalu paket berbayar membuka lebih banyak suara, bahasa, dan karakter bulanan.
Apakah teks ke ucapan sama dengan pembaca layar?
Tidak. Pembaca layar adalah program bantu seperti NVDA, JAWS, VoiceOver, atau TalkBack yang membaca seluruh antarmuka, termasuk menu, tautan, dan kolom formulir. Teks ke ucapan adalah teknologi suara yang mendasari yang digunakan pembaca layar, tetapi TTS sendiri hanya membaca konten yang Anda arahkan padanya, seperti isi sebuah artikel.
Bisakah saya menggunakan suara teks ke ucapan AI secara komersial di blog saya?
Ya, jika penyedia Anda memberikan lisensi suara untuk penggunaan komersial. ElevenLabs, mesin di balik TTSWP, menyertakan hak komersial pada paket berbayar. Anda tetap perlu membaca ketentuannya untuk kasus penggunaan spesifik Anda, terutama untuk podcast berbayar, iklan, atau penjualan kembali audio. Untuk blog standar dengan versi audio dari artikel Anda sendiri, penggunaan komersial sudah tercakup.
Seberapa alami suara teks ke ucapan AI saat ini?
TTS generatif modern terdengar sangat mirip manusia dalam mendengarkan biasa. Sebagian besar pendengar tidak langsung mengenalinya sebagai suara sintetis pada pendengaran pertama. Narasi panjang, dialog ekspresif, dan aksen kental masih menjadi area di mana terkadang bisa dikenali. Untuk artikel berita, posting blog, dan deskripsi produk, perbedaannya dengan pembaca manusia sudah cukup kecil sehingga sebagian besar penerbit menganggapnya sudah terpecahkan.
Apakah teks ke ucapan bekerja dalam bahasa selain bahasa Inggris?
Ya. TTS generatif berkualitas mendukung puluhan bahasa dengan suara yang terdengar seperti penutur asli, termasuk bahasa-bahasa utama Eropa, Asia, dan Timur Tengah. TTSWP memetakan satu suara per bahasa sehingga situs multibahasa menarasikan setiap terjemahan dengan benar. Anda mengonfigurasinya sekali di pengaturan, dan artikel baru otomatis menggunakan suara yang tepat.
Langkah selanjutnya
Jika Anda menerbitkan di WordPress dan ingin versi audio dari setiap artikel tanpa perlu merekam apa pun sendiri, cara tercepat adalah menginstal Teks ke Ucapan - TTSWP, menghubungkan situs Anda, dan memilih suara. Anda bisa mulai secara gratis dan mendapatkan file audio pertama dalam beberapa menit. Setelah itu, yang perlu Anda lakukan hanyalah terus menulis.
Artikel terkait
European Accessibility Act dan WordPress: Panduan Kepatuhan 2026
Apa arti European Accessibility Act bagi pemilik situs WordPress di 2026, siapa yang wajib mematuhinya, besaran denda, dan pernyataan aksesibilitas yang jarang dibahas.

Kepatuhan Audio WCAG 2.2 untuk WordPress: Panduan 2026
Audio WordPress harus memenuhi kriteria WCAG 2.2 termasuk ukuran target, akses keyboard, dan kontrol audio. Berikut daftar periksa kepatuhan 2026 yang praktis.

Teks ke Ucapan untuk TranslatePress: Panduan Lengkap
TranslatePress menerjemahkan HTML yang sudah dirender, bukan membuat duplikat postingan. Begini cara membuat teks ke ucapan cocok di setiap bahasa tanpa audio yang bermasalah.