Qu'est-ce que la synthèse vocale ? Guide clair et pratique

La synthèse vocale (TTS), aussi appelée lecture à voix haute ou text-to-speech, est un logiciel qui convertit du texte écrit en audio. Le système analyse chaque phrase, détermine comment elle doit sonner et produit un fichier audio ou une lecture en direct. Les systèmes d'IA modernes génèrent des voix proches d'un narrateur humain, ce qui explique leur présence sur des sites web, des applications et des outils d'accessibilité au quotidien.
Ce guide explique ce qu'est la synthèse vocale, comment elle fonctionne, ce que l'arrivée des voix IA a changé et comment les propriétaires de sites WordPress l'utilisent concrètement. Pour aller plus loin, notre tutoriel sur comment ajouter la synthèse vocale à WordPress prend le relais à la fin de cet article.
Comment fonctionne la synthèse vocale ?
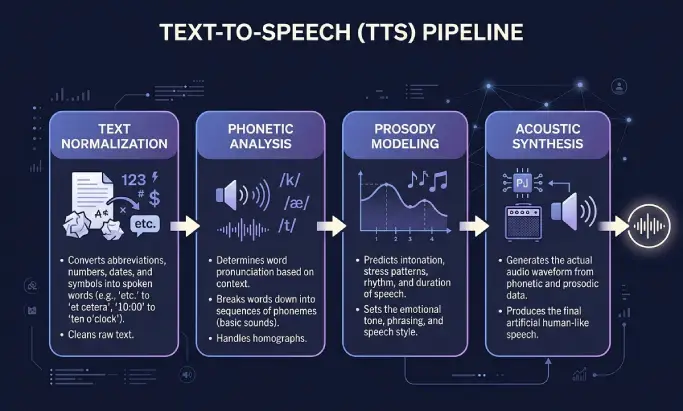
La synthèse vocale repose sur deux étapes. La première traite le texte, la seconde génère l'audio. La plupart des utilisateurs ne voient que le résultat, mais ces étapes expliquent pourquoi certaines voix sonnent robotiques et d'autres semblent humaines.
Normalisation du texte
Le système commence par nettoyer le texte. Il développe les abréviations, détermine comment prononcer les chiffres, les dates, les devises et les acronymes, puis supprime la mise en forme qui ne doit pas être lue. « Dr. Martin a gagné 1 200 € le 12/05 » devient quelque chose que le moteur peut prononcer sans ambiguïté.
Analyse phonétique
Ensuite, le moteur convertit les mots en phonèmes, les plus petites unités sonores d'une langue. C'est là qu'interviennent les règles de prononciation, les dictionnaires et les modèles linguistiques. Les bons systèmes gèrent correctement les homographes : « fils » le descendant et « fils » le fil ne se prononcent pas pareil, et le moteur le sait.
Modélisation de la prosodie
La prosodie désigne le rythme, l'accentuation et l'intonation de la parole. Une question monte à la fin. Une liste marque de petites pauses entre les éléments. Une phrase grave sonne différemment d'une phrase enjouée. Bien modéliser la prosodie, c'est la frontière entre un lecteur robotique et un narrateur qu'on a envie d'écouter.
Synthèse acoustique
Enfin, le moteur génère la forme d'onde. Les anciens systèmes assemblaient des fragments audio pré-enregistrés. Les moteurs neuronaux et génératifs actuels prédisent directement l'audio à partir du texte grâce à l'apprentissage profond. Le résultat est généralement un fichier MP3 ou similaire à 44,1 kHz, qui peut être diffusé en streaming sur votre site ou téléchargé comme un podcast.
Des voix robotiques aux voix IA
Les premiers systèmes de synthèse vocale étaient concaténatifs : ils assemblaient de petits clips enregistrés par un locuteur réel, d'où un rendu saccadé. Le TTS neuronal a remplacé cette approche par des modèles statistiques qui prédisent les caractéristiques vocales, produisant un résultat plus fluide. La génération actuelle utilise l'IA générative entraînée sur de grands corpus de parole, ce qui capture la prosodie, la respiration et le ton émotionnel comme les anciens systèmes n'y parvenaient pas.
C'est pourquoi un article publié en 2026 peut être narré dans une voix que la plupart des auditeurs ne distinguent pas d'un humain à l'écoute ordinaire. Notre bibliothèque de voix, propulsée par ElevenLabs, appartient à cette dernière génération. Vous pouvez prévisualiser les options disponibles dans la documentation des voix.
Qui utilise la synthèse vocale et pourquoi ?
La synthèse vocale est plus répandue qu'on ne le croit. La même technologie de base alimente des produits très différents.
- Les outils d'accessibilité pour les personnes malvoyantes, dyslexiques, peu alphabétisées ou ayant des difficultés d'attention.
- Les versions audio d'articles sur les sites d'actualité, les blogs et les magazines, pour que les lecteurs puissent écouter en se déplaçant ou en faisant autre chose.
- Les plateformes e-learning qui narrent des cours, des quiz et des guides de révision en plusieurs langues.
- Les voix off pour les vidéos explicatives, les contenus YouTube et les démonstrations produit, évitant de faire appel à un comédien à chaque mise à jour.
- L'audio produit WooCommerce qui lit les descriptions à voix haute, pratique pour les acheteurs sur mobile ou ayant des difficultés de lecture. Nous détaillons cela dans notre guide TTS pour les produits WooCommerce.
- Les assistants virtuels et les systèmes SVI, dont la voix des enceintes connectées, des applications de navigation et des lignes de support téléphonique.
Quels sont les avantages de la synthèse vocale pour les propriétaires de sites ?
Si vous gérez un blog, un site d'actualité, une boutique en ligne ou une plateforme de formation, la synthèse vocale change ce que votre contenu peut accomplir. Les bénéfices se cumulent sur l'accessibilité, la portée, l'engagement et les coûts.
Accessibilité et conformité légale
Une version audio de votre contenu écrit aide les utilisateurs qui ont du mal à lire à l'écran. Elle contribue à la conformité avec les Règles d'accessibilité du contenu Web et la Loi européenne sur l'accessibilité, entrée en vigueur pour de nombreux services numériques en juin 2025. Nous détaillons les exigences pratiques dans nos articles sur les exigences audio WCAG pour WordPress et la Loi européenne sur l'accessibilité pour les sites WordPress.
Une audience plus large
Certains lecteurs préféreront écouter même s'ils pourraient lire. Les personnes en déplacement, les parents avec de jeunes enfants, les sportifs et celles qui préfèrent simplement l'audio deviennent accessibles. Vous ne remplacez pas l'article. Vous offrez une deuxième façon de le consommer.
Plus de temps passé sur la page
La lecture audio maintient les utilisateurs sur la page pendant toute la durée de l'article, au lieu d'un défilement rapide. Même une écoute partielle ajoute un temps mesurable sur la page, un signal que Google et les systèmes de recommandation prennent en compte. Sur nos sites, les articles avec un lecteur audio affichent une durée de session moyenne plus longue que les mêmes articles sans lecteur.
AEO et citations par les moteurs de recherche IA
Les moteurs de réponse comme Google AI Overviews, Perplexity et ChatGPT Search citent de plus en plus les contenus bien structurés disposant de médias complémentaires. L'audio est l'un de ces signaux. Nous avons consacré une analyse complète à ce sujet dans pourquoi les moteurs de recherche IA favorisent les articles avec audio.
Audio multilingue sans re-enregistrement
Si votre site est traduit avec Weglot, WPML ou Polylang, la synthèse vocale moderne peut narrer chaque version linguistique automatiquement avec une voix native pour chaque langue. Nous avons documenté ce processus dans notre guide synthèse vocale avec Weglot. Re-enregistrer un comédien pour chaque langue coûte cher. Associer une voix par langue prend quelques minutes.
Moins cher que faire appel à des comédiens
Un narrateur professionnel pour un seul article de 1 500 mots peut coûter plus qu'un mois de crédits TTS génératif couvrant l'ensemble de votre blog. Pour la plupart des éditeurs, le calcul est sans appel. La contrepartie, c'est le contrôle créatif, ce qui explique que certains podcasts et campagnes de marque font encore appel à des talents humains. Pour les articles quotidiens, la narration IA l'emporte.
Synthèse vocale et reconnaissance vocale : quelle différence ?
La synthèse vocale et la reconnaissance vocale sont deux opérations inverses. La synthèse vocale prend du texte et produit de l'audio. La reconnaissance vocale prend de l'audio et produit du texte. Elles résolvent des problèmes différents et apparaissent souvent dans les mêmes produits.
| Fonction | Synthèse vocale (TTS) | Reconnaissance vocale (STT) |
|---|---|---|
| Entrée | Texte écrit | Audio parlé |
| Sortie | Fichier audio ou lecture en direct | Transcription écrite |
| Usage courant | Narration d'articles, voix off, assistants | Transcription, dictée, sous-titres, recherche |
| Aussi appelée | Lecture à voix haute, text-to-speech | ASR, reconnaissance de la parole |
La plupart des plateformes audio modernes intègrent les deux. Un hébergeur de podcasts peut utiliser la reconnaissance vocale pour transcrire un épisode et la synthèse vocale pour générer un résumé audio dans une autre langue.
Comment ajouter la synthèse vocale à votre site ?
Sur WordPress, la synthèse vocale s'ajoute via un plugin. Celui-ci gère la sélection de la voix, la génération automatique à la publication et le lecteur audio affiché à vos visiteurs. Synthèse vocale - TTSWP est notre réponse à cette catégorie, conçue pour les éditeurs plutôt que pour les développeurs.
Vous pouvez comparer les options dans notre sélection des meilleurs plugins de synthèse vocale pour WordPress, ou aller directement voir ce que TTSWP propose et les tarifs. Le guide d'installation étape par étape se trouve dans notre guide de configuration.
Questions fréquentes
Qu'est-ce que la synthèse vocale en termes simples ?
La synthèse vocale est un logiciel qui lit du texte écrit à voix haute. Vous lui fournissez un paragraphe ou un article, et il renvoie un fichier audio ou une lecture en direct dans la voix et la langue choisies. C'est la même technologie qui propulse les versions audio des articles de presse, les lecteurs d'écran, les assistants vocaux et la voix d'annonce dans les applications de navigation.
À quoi sert la synthèse vocale ?
La synthèse vocale sert à l'accessibilité, aux versions audio de contenus écrits, à la narration e-learning, aux voix off de vidéos, à la lecture des descriptions produit dans les boutiques en ligne et aux assistants virtuels. Les sites web l'utilisent pour transformer des articles en audio écoutable. Les applications l'utilisent pour lire des messages, des indications et des alertes. Les établissements scolaires l'utilisent pour rendre les supports de cours accessibles à davantage d'apprenants.
La synthèse vocale est-elle gratuite ?
Certaines solutions de synthèse vocale sont gratuites, mais la qualité varie. Les systèmes d'exploitation intègrent un TTS basique sans frais, et les navigateurs exposent une Web Speech API gratuite. Ces voix sonnent nettement robotiques. Les voix IA de haute qualité, comme celles d'ElevenLabs, fonctionnent sur un modèle de crédits. TTSWP propose un niveau gratuit pour tester l'expérience, puis les offres payantes débloquent davantage de voix, de langues et de caractères mensuels.
La synthèse vocale est-elle la même chose qu'un lecteur d'écran ?
Non. Un lecteur d'écran est un programme d'assistance comme NVDA, JAWS, VoiceOver ou TalkBack qui lit l'intégralité de l'interface : menus, liens et champs de formulaire. La synthèse vocale est la technologie vocale sous-jacente qu'utilise un lecteur d'écran, mais le TTS seul ne lit que le contenu qu'on lui indique, comme le corps d'un article.
Puis-je utiliser des voix IA commercialement sur mon blog ?
Oui, si votre fournisseur vous accorde une licence d'utilisation commerciale. ElevenLabs, le moteur derrière TTSWP, inclut les droits commerciaux dans les offres payantes. Lisez tout de même les conditions pour votre usage spécifique, notamment pour les podcasts monétisés, les publicités ou la revente d'audio. Pour un blog standard avec des versions audio de vos propres articles, l'usage commercial est couvert.
Les voix IA sonnent-elles naturellement aujourd'hui ?
Le TTS génératif moderne sonne proche d'un humain à l'écoute ordinaire. La plupart des auditeurs ne le détectent pas comme synthétique au premier passage. La narration longue, les dialogues expressifs et les accents marqués restent les cas où l'on peut parfois faire la différence. Pour les articles d'actualité, les billets de blog et les descriptions produit, l'écart avec un lecteur humain est suffisamment faible pour que la plupart des éditeurs le considèrent résolu.
La synthèse vocale fonctionne-t-elle dans d'autres langues que le français ?
Oui. Le TTS génératif de qualité prend en charge des dizaines de langues avec des voix au son natif, dont les principales langues européennes, asiatiques et du Moyen-Orient. TTSWP associe une voix par langue pour qu'un site multilingue narre chaque traduction correctement. Vous configurez cela une seule fois dans les réglages, et les nouveaux articles utilisent automatiquement la bonne voix.
Et maintenant ?
Si vous publiez sur WordPress et souhaitez une version audio de chaque article sans rien enregistrer vous-même, le chemin le plus rapide est d'installer Synthèse vocale - TTSWP, de connecter votre site et de choisir une voix. Vous pouvez commencer gratuitement et avoir le premier fichier audio généré en quelques minutes. Après ça, il ne vous reste plus qu'à écrire.
Articles connexes
Loi européenne sur l'accessibilité et WordPress : guide de conformité 2026
Ce que la loi européenne sur l'accessibilité signifie pour les propriétaires de sites WordPress en 2026 : qui est concerné, les sanctions et la déclaration d'accessibilité que personne ne mentionne.

Conformité audio WCAG 2.2 pour WordPress : guide 2026
L'audio WordPress doit respecter les critères WCAG 2.2, notamment la taille des cibles, la navigation au clavier et le contrôle du son. Voici la liste de conformité pratique pour 2026.

Synthèse vocale avec TranslatePress : ce qui fonctionne vraiment
TranslatePress traduit le HTML rendu, pas des articles dupliqués. Voici comment faire correspondre la synthèse vocale à chaque langue sans audio défaillant.