Cos'è la sintesi vocale? Una guida in parole semplici

La sintesi vocale (Text to Speech, TTS), chiamata anche lettura ad alta voce o produzione vocale artificiale, è un software che converte il testo scritto in audio parlato. Il sistema legge una frase, analizza come dovrebbe suonare e produce un file audio o una riproduzione in tempo reale. I moderni sistemi di sintesi vocale con IA generano voci che si avvicinano molto a un narratore umano, ed è per questo che siti web, app e strumenti di assistenza li usano ogni giorno.
Questa guida spiega cos'è la sintesi vocale, come funziona internamente, cosa è cambiato con l'arrivo delle voci generate dall'IA e come i proprietari di siti web la usano su WordPress. Per una guida pratica dopo questa lettura, il nostro articolo su come aggiungere la sintesi vocale a WordPress parte esattamente da dove finisce questo.
Come funziona la sintesi vocale?
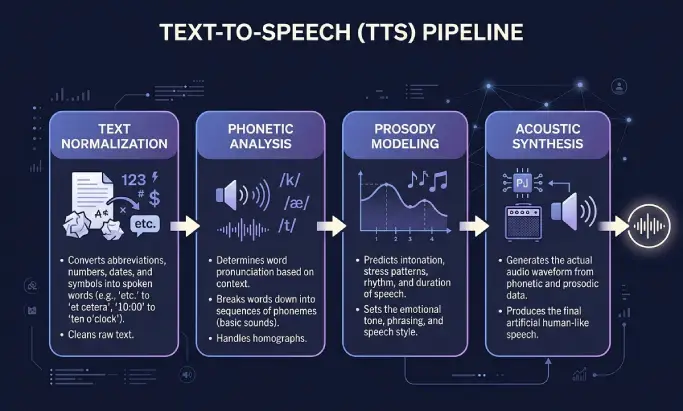
La sintesi vocale funziona in due fasi. La prima elabora il testo scritto, la seconda genera l'audio. La maggior parte degli utenti vede solo il risultato, ma i passaggi intermedi spiegano perché alcune voci suonano piatte e altre sembrano umane.
Normalizzazione del testo
Per prima cosa, il sistema pulisce il testo in ingresso. Espande le abbreviazioni, decide come leggere numeri, date, valute e acronimi, e rimuove la formattazione che non deve essere pronunciata. «Dott. Rossi ha guadagnato 1.200 € il 5/12» diventa qualcosa che il motore può pronunciare senza incertezze.
Analisi fonetica
Il motore converte poi le parole in fonemi, le unità minime di suono di una lingua. Qui entrano in gioco le regole di pronuncia, i dizionari e i modelli linguistici. I buoni sistemi gestiscono correttamente gli omografi, così «pesca» il frutto e «pesca» l'attività suonano in modo diverso secondo il contesto.
Modellazione della prosodia
La prosodia è il ritmo, l'accento e l'intonazione del parlato. Una domanda si alza alla fine. Un elenco ha piccole pause tra gli elementi. Una frase seria suona diversamente da una allegra. Modellare bene la prosodia è la differenza tra una voce robotica e un narratore che vale la pena ascoltare.
Sintesi acustica
Infine, il motore genera la forma d'onda. I sistemi più vecchi incollavano insieme frammenti audio pre-registrati. I moderni motori neurali e generativi predicono l'audio direttamente dal testo usando il deep learning. Il risultato è solitamente un file MP3 o simile a 44,1 kHz, che può essere trasmesso in streaming sul sito o scaricato come podcast.
Dalle voci robotiche alle voci generate dall'IA
I primi sistemi di sintesi vocale erano concatenativi: incollavano piccoli frammenti registrati da un parlante reale, ed è per questo che suonavano frammentati. Il TTS neurale ha sostituito questo approccio con modelli statistici che predicono le caratteristiche del parlato, producendo un output più fluido. L'attuale generazione usa IA generativa addestrata su grandi dataset vocali, che cattura prosodia, respiro e tono emotivo in modo impossibile per i vecchi sistemi.
Questo cambiamento spiega perché un articolo pubblicato nel 2026 può essere narrato da una voce che la maggior parte degli ascoltatori non distingue da una umana in ascolto normale. La nostra libreria vocale, alimentata da ElevenLabs, appartiene a questa ultima generazione. Puoi visualizzare in anteprima le opzioni disponibili nella documentazione delle voci.
Chi usa la sintesi vocale e perché?
La sintesi vocale è presente in più contesti di quanti la maggior parte delle persone immagini. La stessa tecnologia di base alimenta prodotti molto diversi tra loro.
- Strumenti di accessibilità per lettori con disabilità visiva, dislessia, difficoltà di lettura o problemi di attenzione.
- Versioni audio degli articoli su siti di notizie, blog e riviste, così i lettori possono ascoltare mentre si spostano o fanno altro.
- Piattaforme di e-learning che narrano lezioni, quiz e guide di studio in più lingue.
- Voci fuori campo per video esplicativi, contenuti YouTube e demo di prodotti, eliminando il costo di assumere un attore vocale per ogni aggiornamento.
- Audio dei prodotti WooCommerce che legge le descrizioni ad alta voce, utile per gli acquirenti da mobile o con difficoltà di lettura. Ne parliamo in dettaglio nella nostra guida alla sintesi vocale per i prodotti WooCommerce.
- Assistenti virtuali e sistemi IVR, inclusa la voce degli altoparlanti intelligenti, delle app di navigazione e delle linee di assistenza clienti.
Quali vantaggi offre la sintesi vocale ai proprietari di siti web?
Se gestisci un blog, un sito di notizie, un negozio online o una piattaforma di corsi, la sintesi vocale cambia quello che i tuoi contenuti possono fare. I vantaggi si sommano su accessibilità, portata, coinvolgimento e costi.
Accessibilità e conformità normativa
Una versione audio del tuo contenuto scritto aiuta gli utenti che non riescono a leggere comodamente dallo schermo. Supporta la conformità alle Linee guida per l'accessibilità dei contenuti web (WCAG) e alla Direttiva europea sull'accessibilità, entrata in vigore per molti servizi digitali a giugno 2025. Analizziamo i requisiti pratici nei nostri articoli sui requisiti audio WCAG per WordPress e sulla Direttiva europea sull'accessibilità per i siti WordPress.
Pubblico più ampio
Alcuni lettori preferiranno ascoltare anche quando potrebbero leggere. Chi si sposta, i genitori con bambini piccoli, chi si allena in palestra e chi semplicemente preferisce l'audio diventano tutti raggiungibili. Non stai sostituendo l'articolo. Stai aggiungendo un secondo modo per fruirlo.
Tempo di permanenza e coinvolgimento maggiori
La riproduzione audio mantiene gli utenti sulla pagina per tutta la durata dell'articolo invece di una rapida scorsa. Anche gli ascolti parziali aggiungono tempo misurabile sulla pagina, un segnale a cui sia Google che i sistemi di raccomandazione prestano attenzione. Nella nostra esperienza, gli articoli con player audio registrano una durata media della sessione più alta rispetto agli stessi articoli senza.
AEO e citazioni dai motori di risposta basati su IA
Motori di risposta come Google AI Overviews, Perplexity e ChatGPT Search citano sempre più spesso contenuti ben strutturati con media di supporto. L'audio è uno di questi segnali. Ne abbiamo scritto un'analisi dedicata in perché i motori di ricerca IA preferiscono gli articoli con audio.
Audio multilingua senza registrare di nuovo
Se il tuo sito è tradotto con Weglot, WPML o Polylang, il TTS moderno può narrare automaticamente ogni versione linguistica con una voce dal suono naturale per quella lingua. Abbiamo documentato questo flusso di lavoro nella nostra guida alla sintesi vocale con Weglot. Registrare di nuovo una voce umana per ogni lingua è costoso. Assegnare una voce per lingua richiede pochi minuti.
Costi inferiori rispetto agli attori vocali
Un narratore professionista per un singolo articolo da 1.500 parole può costare più di un mese di crediti TTS generativo che copre l'intero blog. Per la maggior parte degli editori il calcolo non è nemmeno vicino. Il compromesso è il controllo creativo, motivo per cui alcuni podcast e campagne di brand usano ancora talenti umani. Per gli articoli quotidiani, la narrazione IA vince.
Sintesi vocale e riconoscimento vocale: qual è la differenza?
La sintesi vocale e il riconoscimento vocale sono opposti. La sintesi vocale prende parole scritte e produce audio. Il riconoscimento vocale prende audio e produce testo scritto. Risolvono problemi diversi e spesso compaiono nello stesso prodotto.
| Caratteristica | Sintesi vocale (TTS) | Riconoscimento vocale (STT) |
|---|---|---|
| Input | Testo scritto | Audio parlato |
| Output | File audio o riproduzione in tempo reale | Trascrizione scritta |
| Uso comune | Narrazione di articoli, voci fuori campo, assistenti | Trascrizione, dettatura, sottotitoli, ricerca |
| Chiamato anche | Lettura ad alta voce, produzione vocale | ASR, riconoscimento vocale |
La maggior parte delle piattaforme audio moderne include entrambi. Un host di podcast potrebbe usare STT per trascrivere un episodio e TTS per generare un riassunto audio in un'altra lingua.
Come si aggiunge la sintesi vocale al proprio sito?
Su WordPress, la sintesi vocale si aggiunge con un plugin. Il plugin gestisce la selezione della voce, la generazione automatica al momento della pubblicazione e il player audio che vedono i tuoi visitatori. Sintesi vocale - TTSWP è la nostra risposta a questa categoria, costruita per gli editori e non per gli sviluppatori.
Puoi confrontare le opzioni nella nostra selezione dei migliori plugin di sintesi vocale per WordPress, oppure vai direttamente a cosa può fare TTSWP e ai prezzi. L'installazione passo dopo passo è spiegata nella nostra guida all'installazione.
Domande frequenti
Cos'è la sintesi vocale in parole semplici?
La sintesi vocale è un software che legge il testo scritto ad alta voce. Gli fornisci un paragrafo o un articolo e restituisce un file audio o una riproduzione in tempo reale nella voce e nella lingua scelta. È la stessa tecnologia alla base delle versioni audio degli articoli di notizie, degli screen reader, degli assistenti vocali e della voce delle app di navigazione.
A cosa serve la sintesi vocale?
La sintesi vocale è usata per l'accessibilità, le versioni audio di contenuti scritti, la narrazione nei corsi online, le voci fuori campo per video, l'audio delle descrizioni prodotto negli store online e gli assistenti virtuali. I siti web la usano per trasformare gli articoli in audio ascoltabile. Le app la usano per leggere messaggi, indicazioni stradali e avvisi. Le scuole la usano per rendere il materiale di studio accessibile a più studenti.
La sintesi vocale è gratuita?
Alcune soluzioni di sintesi vocale sono gratuite, ma la qualità varia. I sistemi operativi includono un TTS di base senza costi, e i browser espongono una Web Speech API gratuita. Queste voci suonano chiaramente robotiche. Le voci IA di alta qualità di provider come ElevenLabs usano un modello a crediti. TTSWP offre un piano gratuito per testare l'esperienza; i piani a pagamento sbloccano più voci, lingue e caratteri mensili.
La sintesi vocale è uguale a uno screen reader?
No. Uno screen reader è un programma assistivo come NVDA, JAWS, VoiceOver o TalkBack che legge l'intera interfaccia, inclusi menu, link e campi modulo. La sintesi vocale è la tecnologia vocale sottostante usata da uno screen reader, ma da sola legge solo il contenuto che gli indichi, come il corpo di un articolo.
Posso usare le voci IA per la sintesi vocale commercialmente sul mio blog?
Sì, se il tuo fornitore concede la licenza per uso commerciale. ElevenLabs, il motore alla base di TTSWP, include i diritti commerciali nei piani a pagamento. Dovresti comunque leggere i termini per il tuo caso d'uso specifico, specialmente per podcast monetizzati, annunci o rivendita di audio. Per un blog standard con versioni audio dei propri articoli, l'uso commerciale è coperto.
Quanto suonano naturali le voci IA per la sintesi vocale oggi?
Il TTS generativo moderno suona molto vicino a una voce umana in ascolto normale. La maggior parte degli ascoltatori non lo identifica come sintetico al primo ascolto. La narrazione lunga, i dialoghi espressivi e gli accenti marcati sono ancora i casi in cui a volte si può capire. Per articoli di notizie, post del blog e descrizioni prodotto, il divario con un lettore umano è abbastanza ridotto da essere considerato risolto dalla maggior parte degli editori.
La sintesi vocale funziona in lingue diverse dall'inglese?
Sì. Il TTS generativo di qualità supporta decine di lingue con voci dal suono naturale, incluse le principali lingue europee, asiatiche e mediorientali. TTSWP assegna una voce per lingua, così un sito multilingua narra correttamente ogni traduzione. Lo configuri una volta nelle impostazioni e i nuovi articoli usano automaticamente la voce giusta.
Come proseguire
Se pubblichi su WordPress e vuoi una versione audio di ogni articolo senza registrare nulla tu stesso, il percorso più rapido è installare Sintesi vocale - TTSWP, collegare il tuo sito e scegliere una voce. Puoi iniziare gratuitamente e avere il primo file audio generato in pochi minuti. Da lì in poi, resta solo da scrivere.
Articoli correlati
European Accessibility Act e WordPress: Guida alla conformità 2026
Cosa significa l'European Accessibility Act per i proprietari di siti WordPress nel 2026: chi deve adeguarsi, le sanzioni previste e la dichiarazione di accessibilità che quasi nessuno considera.

Conformità audio WCAG 2.2 per WordPress: Guida 2026
L'audio su WordPress deve soddisfare i criteri WCAG 2.2 su dimensioni dei target, accesso da tastiera e controllo audio. Ecco la checklist pratica per la conformità 2026.

Sintesi vocale con TranslatePress: cosa funziona davvero
TranslatePress traduce l'HTML già renderizzato, non crea post duplicati. Ecco come far funzionare la sintesi vocale in ogni lingua, senza audio rotti.