AEO en Audio: Waarom Artikelen met Audio Vaker door AI worden Geciteerd
AI-zoekmachines kunnen WordPress-artikelen direct citeren als die een audioversie bevatten die is opgemaakt met AudioObject JSON-LD-schema. Audio toevoegen creëert een parallel gestructureerd signaal dat de kans vergroot om geciteerd te worden in Perplexity, ChatGPT Search, Google AI Mode en AI Overviews. We hebben gezien hoe Tekst naar Spraak - TTSWP zelf als geciteerde bron verscheen in Google AI Mode bij zoekopdrachten naar text to speech wordpress. Dat is het praktische bewijs dat we hieronder uitleggen.
Dit artikel is bedoeld voor WordPress-uitgevers, contentmarketeers en SEO-specialisten die al vertrouwd zijn met traditionele SEO en nu willen uitbreiden naar AEO. Answer Engine Optimization is het structureren van content zodat AI-engines die kunnen extraheren en citeren. We richten ons op één ondergewaardeerde hefboom: audio.
Het bewijs: TTSWP geciteerd in Google AI Mode
We hebben het zelf gezien. Een zoekopdracht naar text to speech wordpress in Google AI Mode leverde een AI-gegenereerd overzicht op dat TTSWP naast GSpeech noemde en voor Amazon Polly plaatste. Dit was geen betaalde plaatsing. Google AI Mode koos de bron op basis van contentsignalen die het van onze pagina's kon lezen. Onze 2026-ranglijst van WordPress TTS-plugins zet de sterke en zwakke punten van elk per stuk uiteen.
Het relevante feit: onze belangrijkste artikelen bevatten zowel Article-schema als AudioObject-schema. De audioversie staat op de pagina, de transcriptie komt overeen met de artikeltekst en de duur is opgegeven in ISO 8601-formaat. We geloven dat deze combinatie mede de reden is waarom onze content werd opgepikt.
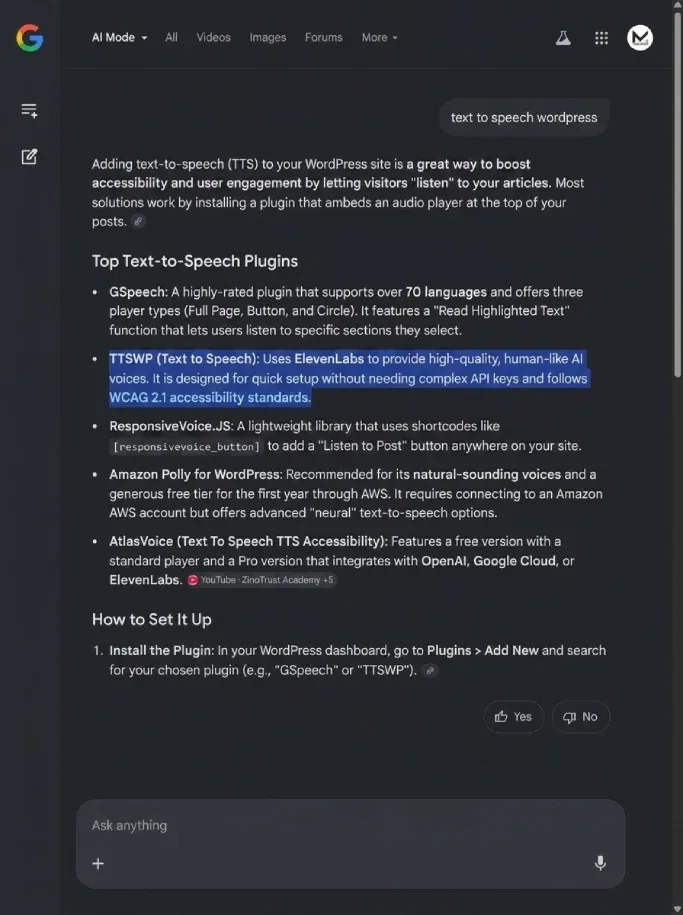
Één datapunt is geen wet. Maar het is een werkend voorbeeld dat lezers kunnen nabootsen, en dat is de praktische kern van dit artikel.
Hoe AI-zoekmachines audiocontent verwerken in 2026
Elke engine gaat anders om met audio. We vatten samen wat publiekelijk bekend is en geven aan wat onduidelijk blijft.
Perplexity indexeert pagina's en toont bronnen per URL. Het leest gestructureerde data wanneer die aanwezig is en gebruikt schema om te bevestigen wat een pagina bevat. AudioObject helpt Perplexity bevestigen dat een pagina een media-alternatief voor tekst biedt.
ChatGPT Search combineert live webopvraging met geïndexeerde pagina's. Het leest JSON-LD tijdens het crawlen. We zien citaties clusteren rond pagina's met uitgebreide gestructureerde data.
Google AI Mode en AI Overviews zijn gebaseerd op dezelfde onderliggende index als Google Zoeken. Gestructureerde data die al wordt ondersteund in Google Zoeken wordt hier ook verwerkt, inclusief AudioObject. Dit is vandaag de meest directe route van audiomarkering naar AI-citatie.
Claude gebruikt zoekopvraging wanneer browsen is ingeschakeld. Het citatiegedrag is minder goed gedocumenteerd. We hebben gezien dat het TTSWP-pagina's citeert in Claude met webzoekopdrachten ingeschakeld, maar we kunnen dat niet specifiek aan audio koppelen.
De eerlijke conclusie: Google AI Mode en AI Overviews zijn vandaag de engines die het meest waarschijnlijk reageren op AudioObject-schema, omdat Google het al ondersteunt in klassieke zoekresultaten. De andere engines profiteren indirect van dezelfde gestructureerde signalen.
AudioObject JSON-LD: het ondergewaardeerde AEO-signaal
De meeste WordPress-uitgevers voegen Article-schema toe en stoppen daar. AudioObject toevoegen kost vijf minuten en creëert een tweede gestructureerd signaal dat AI-engines kunnen verwerken.
Hier is een volledig voorbeeld dat je kunt aanpassen. Plaats het in een <script type="application/ld+json">-tag in je artikelsjabloon.
{
"@context": "https://schema.org",
"@type": "AudioObject",
"name": "AEO en Audio: Waarom Artikelen met Audio Vaker door AI worden Geciteerd",
"description": "Audio-narration van het artikel over het toevoegen van AudioObject-schema aan WordPress-berichten.",
"contentUrl": "https://example.com/audio/aeo-en-audio.mp3",
"encodingFormat": "audio/mpeg",
"duration": "PT8M42S",
"inLanguage": "nl",
"transcript": "https://example.com/blog/aeo-en-audio-ai-citatie",
"isPartOf": {
"@type": "Article",
"@id": "https://example.com/blog/aeo-en-audio-ai-citatie"
}
}Veld voor veld: dit doet elke regel voor AI-engines:
- name: de leesbare titel van de audio. Sluit aan bij de artikeltitel zodat AI-engines ze aan elkaar koppelen.
- contentUrl: de directe URL naar het MP3-bestand. Moet publiek toegankelijk zijn, niet achter een login.
- encodingFormat: het MIME-type.
audio/mpegvoor MP3. - duration: ISO 8601-formaat.
PT8M42Sbetekent 8 minuten en 42 seconden. Gebruik dit formaat exact. Gewone tekst zoals "8:42" wordt niet verwerkt. - inLanguage: BCP-47-taaltag. Vertelt AI-engines voor welk publiek deze content geciteerd moet worden. Cruciaal voor meertalige sites.
- transcript: een URL naar de bijbehorende tekst. Deze naar de artikel-URL laten wijzen signaleert dat de audio een ingesproken versie is van de pagina-inhoud.
- isPartOf: koppelt de audio aan het bovenliggende artikel. Dit is het onderdeel dat de meeste uitgevers overslaan.
Voor volledige implementatiedetails en de bijbehorende WordPress-hooks, zie onze handleiding voor het toevoegen van tekst-naar-spraak in WordPress. De plugin verwerkt AudioObject-schema automatisch zodra audio is gegenereerd.
Waarom audio de kans op een citatie vergroot
AI-engines wegen de autoriteit van content. Meerdere gestructureerde formaten versterken het signaal. Een pagina met Article-, AudioObject- en BreadcrumbList-schema geeft een engine drie bevestigingen van wat de pagina bevat en hoe die zich tot een site verhoudt.
Audio werkt ook als een zacht vertrouwenssignaal. Audio genereren, hosten en serveren kost tijd en geld. AI-engines meten die investering niet rechtstreeks, maar de gestructureerde output ervan, een verwerkt AudioObject met geldige duur en contentUrl, wijst op een uitgever die op een hoger niveau opereert dan een dunne-content-concurrent.
We spreken over kans, niet over garantie. We zien correlaties in onze eigen analyses. We kunnen geen rankings beloven.
Wat audiocontent citeerwaardig maakt
Niet elk audiobestand helpt AEO even goed. Sommige patronen werken, andere zorgen voor wrijving.
Directe inspraak van de artikeltekst werkt het beste. De audio komt overeen met de transcriptie op de pagina. AI-engines bevestigen de relatie en behandelen de pagina als een bron in meerdere formaten.
Origineel commentaar bovenop het artikel is lastiger. De audio bevat content die nergens als tekst op de pagina staat. AI-engines kunnen dat niet op schaal transcriberen en verifiëren. De audio helpt nog steeds voor toegankelijkheid, maar versterkt citatie niet op dezelfde manier.
Korte tot middellange audio (onder de 15 minuten) wordt verwerkt en gezien als een betekenisvol media-alternatief. Zeer lange audio is moeilijker af te stemmen op tekst en is een minder betrouwbaar signaal.
Audio achter betaal- of loginmuren is onzichtbaar. Als een crawler contentUrl niet kan bereiken, is het schema zinloos.
Hoe je test of AI-zoekmachines jouw content citeren
Hier is het protocol dat we intern gebruiken. Het kost ongeveer 30 minuten per onderwerp, plus één tot twee weken wachten op indexering.
- Kies een onderwerp dat je al behandelt. Kies een artikel met sterke on-page SEO en minimaal één audioversie. Noteer de exacte URL.
- Maak een lijst van drie tot vijf zoekopdrachten die een lezer zou kunnen intypen om dat artikel te vinden. Gebruik natuurlijke taal, geen keywordstuffing.
- Zoek elke zoekopdracht apart op in Perplexity, ChatGPT Search en Google AI Mode. Noteer welke bronnen worden geciteerd in het AI-antwoord. Maak een screenshot van elk resultaat.
- Test directe opvraging in Perplexity door je URL in een zoekopdracht te plakken met de focusoperator. Dit bevestigt of Perplexity de pagina heeft geïndexeerd.
- Valideer je schema met de Rich Results Test van Google. Controleer of AudioObject foutloos wordt gedetecteerd.
- Wacht één tot twee weken na publicatie of bijwerking voordat je opnieuw test. Indexering gaat niet instant.
- Herhaal de zoekopdrachten. Vergelijk citatieposities voor en na. Noteer welke engines je nu citeren die dat eerder niet deden.
Dit is geen perfect attributiemodel. AI-engines veranderen. Je concurrenten veranderen. Maar het protocol geeft je een nulmeting en een herhaalbare test die je elk kwartaal kunt uitvoeren.
Veelgemaakte AEO-fouten bij WordPress-uitgevers met audio
We zien steeds dezelfde fouten tijdens audits. Ze zijn allemaal in minuten op te lossen.
- Audio genereren maar AudioObject-schema overslaan. De audio speelt voor gebruikers, maar AI-engines zien niets gestructureerds. Het signaal gaat verloren.
- Audio hosten achter authenticatie. Audio alleen voor leden kan niet worden geciteerd. Als audio is afgegrendeld, maak dan een publieke voorbeeldversie met eigen schema beschikbaar.
inLanguageweglaten. AI-engines kunnen niet bepalen voor welke taalregio ze deze content moeten citeren. Meertalige uitgevers verliezen hier het meest.- Niet-ISO-duurformaten gebruiken.
8:42,8 min 42 secen00:08:42worden niet verwerkt. GebruikPT8M42S. - De audio niet markeren als ingesproken versie. Stel
transcriptin op de artikel-URL enisPartOfop het Article-schema. Dit vertelt engines dat de audio dezelfde content is als de tekst. - Toegankelijkheid vergeten. Audio-narration voldoet ook aan de WCAG-vereisten voor media-alternatieven. Zie onze WCAG-audiogids voor de overlap tussen toegankelijkheid en AEO-signalen.
Als je dit vanaf nul opzet, behandelt onze documentatie de implementatie van begin tot eind, inclusief hoe TTSWP AudioObject-schema automatisch uitvoert.
Het perspectief van de uitgever
Voor bloggers, journalisten, online publicaties en cursusmakers doet audio twee dingen tegelijk. Het bedient lezers die liever luisteren, wat de tijd op de pagina verlengt en het bereik vergroot. En het creëert gestructureerde data die AI-engines verwerken bij het bepalen wie ze citeren.
Via Mementor, ons moederbedrijf, werken we samen met uitgevers in de Benelux en Europa, en het patroon is consistent. Uitgevers die audio toevoegen met het juiste schema zien binnen een kwartaal meer diverse verkeersbronnen, inclusief AI-engine-verwijzingen die er eerder niet waren. Bekijk onze use cases voor uitgevers voor het volledige plaatje.
Veelgestelde vragen
Helpt audio toevoegen echt bij mijn AI-zoekrangschikking?
Het vergroot de kans op een citatie, geen klassieke ranking. AI-zoekmachines zoals Perplexity, ChatGPT Search en Google AI Mode kiezen bronnen om te citeren in gegenereerde antwoorden. Audio met AudioObject-schema geeft die engines een extra gestructureerd signaal dat de paginaautoriteit en het contenttype bevestigt. We hebben onze eigen pagina's zien verschijnen in Google AI Mode nadat we audio hadden toegevoegd. We kunnen hetzelfde resultaat niet beloven voor elke site, maar het mechanisme is reëel.
Welke AI-zoekmachines citeren audiocontent direct?
Google AI Mode en Google AI Overviews zijn vandaag de duidelijkste gevallen, omdat ze AudioObject-ondersteuning erven van Google Zoeken. Perplexity en ChatGPT Search profiteren indirect: ze lezen JSON-LD tijdens het crawlen en AudioObject versterkt wat een pagina bevat. Claude met webzoeken ingeschakeld citeert pagina's met sterke gestructureerde data, maar de afhandeling van audio is minder goed gedocumenteerd. We beschouwen Google AI Mode als het primaire doel.
Heb ik een apart transcriptiebestand nodig als ik al audio heb?
Nee. Als je audio een directe ingesproken versie is van de artikeltekst, stel dan het veld transcript in AudioObject in op de artikel-URL zelf. Dit vertelt AI-engines dat de paginatekst de transcriptie is. Je hebt alleen een apart transcriptiebestand nodig als de audio content bevat die niet op de pagina staat, zoals origineel commentaar of interviewmateriaal dat niet in het geschreven artikel voorkomt.
Vervangt AudioObject-schema het Article-schema of vult het het aan?
Het vult Article-schema aan. Houd je Article JSON-LD intact en publiceer AudioObject als een tweede script-tag, gekoppeld aan het artikel via het veld isPartOf. Meerdere schematypen op één pagina versterken het signaal dat AI-engines verwerken. Article-schema verwijderen verzwakt je pagina in plaats van hem te versterken. De twee formaten werken samen om de pagina te beschrijven als zowel geschreven content als media.
Hoe lang duurt het voordat je citatieeffecten ziet na het toevoegen van audio?
Reken op één tot twee weken indexeringstijd voordat je test, en een volledig kwartaal om consistente citatiepatronen te zien. Google moet je pagina's opnieuw crawlen en verwerken. AI-engines werken hun ophaalindexen op verschillende schema's bij, sommige dagelijks, sommige wekelijks. Voer het testprotocol uit na één week, vier weken en twaalf weken na publicatie. Vergelijk de resultaten over alle drie de intervallen.
Waar te beginnen
Kies één kernbijdrage op je site, genereer een audioversie, voeg AudioObject-schema toe en voer het testprotocol twee weken later uit. Eén artikel is genoeg om het mechanisme op jouw domein te bevestigen. Schaal daarna op naar de rest van je bibliotheek. Als je wilt dat het schema automatisch wordt verwerkt bij het genereren van audio, installeer dan de TTSWP-plugin en koppel die aan je site. De AudioObject-opmaak wordt standaard meegeleverd, zodat je geen handmatige JSON-LD hoeft bij te houden.
Gerelateerde artikelen
Tekst naar spraak voor Polylang-sites: wat echt werkt
Voeg Polylang tekst naar spraak toe die per vertaling één audiobestand aanmaakt, de juiste stem per taal kiest en bestand blijft bij caching.

Tekst naar Spraak voor WPML-sites: Wat Echt Werkt
Hoe je tekst naar spraak voor WPML instelt die per taal de juiste stem kiest, aparte audiobestanden per vertaling aanmaakt en AJAX-taaldetectieproblemen overleeft.

Wat is tekst naar spraak? Een begrijpelijke uitleg
Tekst naar spraak zet geschreven inhoud om in gesproken audio. Leer hoe het werkt, waarom het belangrijk is en hoe je het toevoegt aan je WordPress-site.